Backup Candidates

Resource Configs Backup
Declarative Approach
A good practice is to store these on source code repositories, that way it can be maintained by a team.
The source code repository should be configured with the right backup solutions.
With managed or public source code repositories like GitHub, you don’t have to worry about this.
With that, even when you lose your entire cluster, you can redeploy your application on the cluster by simply applying these configuration files on them.
While the declarative approach is the preferred approach, it is not necessary that all of your team members stick to those standards.
Imperative Approach

What if someone created an object the imperative way
without documenting that information anywhere?
So a better approach to backing up resource configuration is to query the Kube API server.
Query the Kube API server using the kubectl, or by accessing the API server directly, and save all resource configurations for all objects created on the cluster as a copy.
For example, one of the commands that can be used in a backup script is to get all pods, and deployments, and services in all namespaces using the kubectl utility’s get all command, and extract the output in a YAML format, then save that file.
And that’s just for a few resource group.
There are many other resource groups that must be considered.
Of course, you don’t have to develop that solution yourself.

There are tools like Ark, or now called Velero, by Heptio,
that can do this for you.
It can help in taking backups of your Kubernetes cluster
using the Kubernetes API.
ETCD Backup

The etcd cluster stores information about the state of our cluster.
So information about the cluster itself, the nodes and every other resources created within the cluster, are stored here.
So instead of backing up resource as before, you may choose to backup the etcd server itself.
As we have seen, the etcd cluster is hosted on the master nodes.
While configuring etcd, we specified a location where all the data would be stored, the data directory.

That is the directory that can be configured to be backed up by your backup tool.
Etcd also comes with a builtin snapshot solution.
You can take a snapshot of the etcd database by using the etcd control utility’s snapshot save command.

Give the snapshot a name, snapshot.db. A snapshot file is created by the name in the current directory.
If you want it to be created in another location, specify the full path.
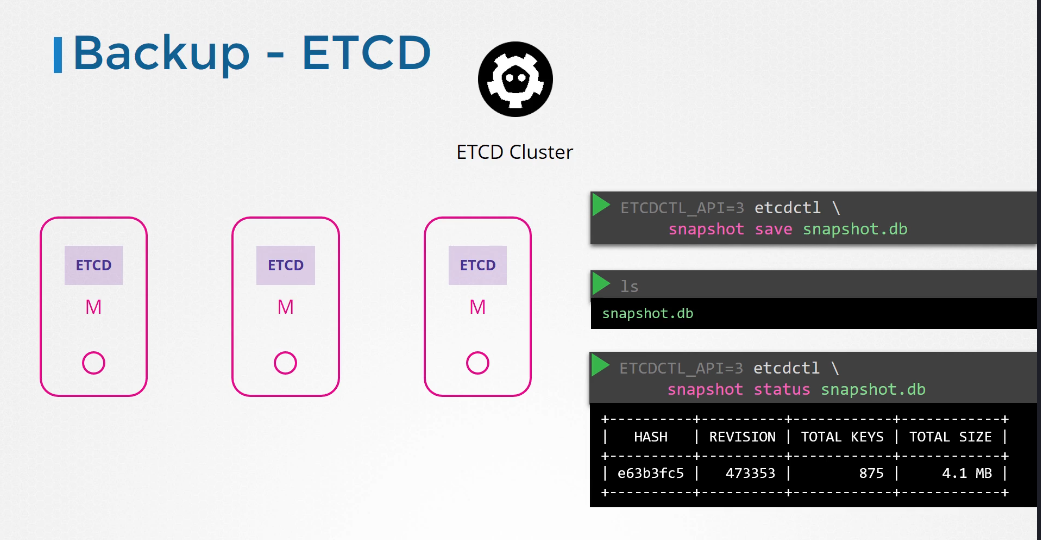 You can view the status of the backup using the snapshot status command.
You can view the status of the backup using the snapshot status command.
To restore the cluster from this backup at a later point in time,

first, stop the Kube API server service, as the restore process will require you to restart the etcd cluster, and the Kube API server depends on it.
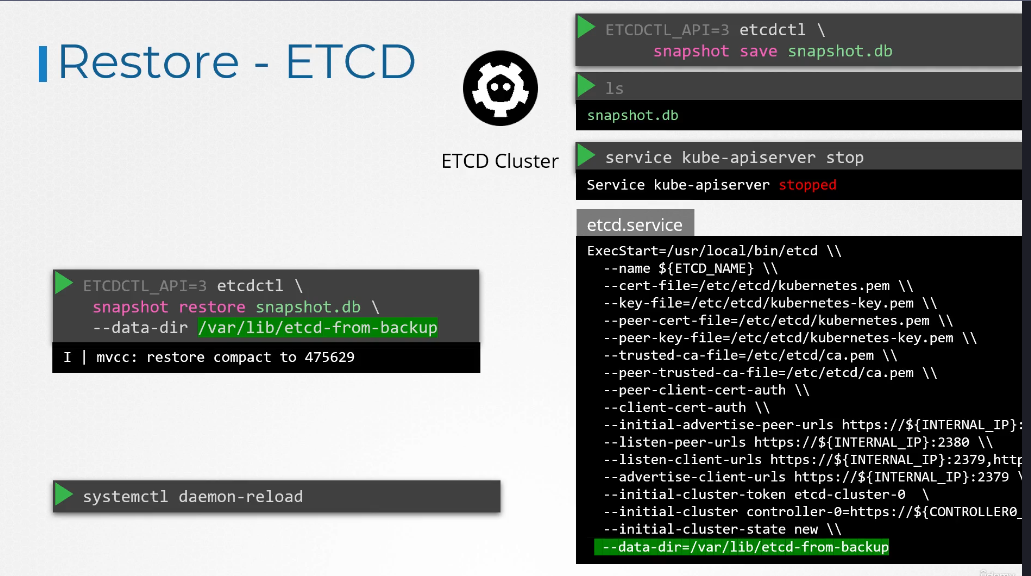
Then, run the etcd controls snapshot restore command, with the path set to the path of the backup file, which is the snapshot.db file
When etcd restores from a backup, in initializes a new cluster configuration and configures the members of etcd as new members to a new cluster.
This is to prevent a new member from accidentally joining an existing cluster.
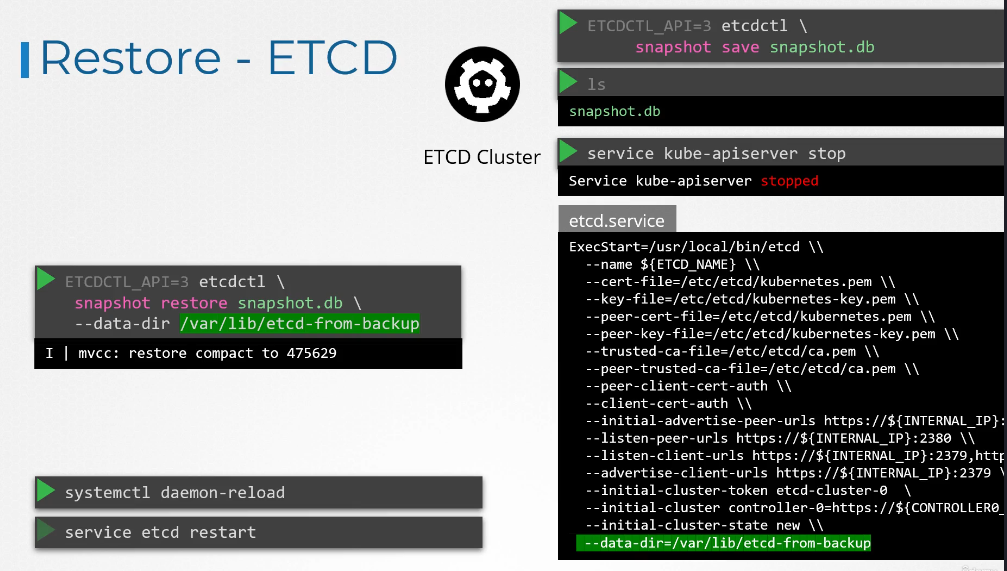
On running this command, a new data directory is created.
In this example, at location var lib etcd from backup.
We then configure the etcd configuration file
to use the new data directory.
Then, reload the service demon and restart etcd service.
Finally, start the Kube API server service.
Your cluster should now be back in the original state.

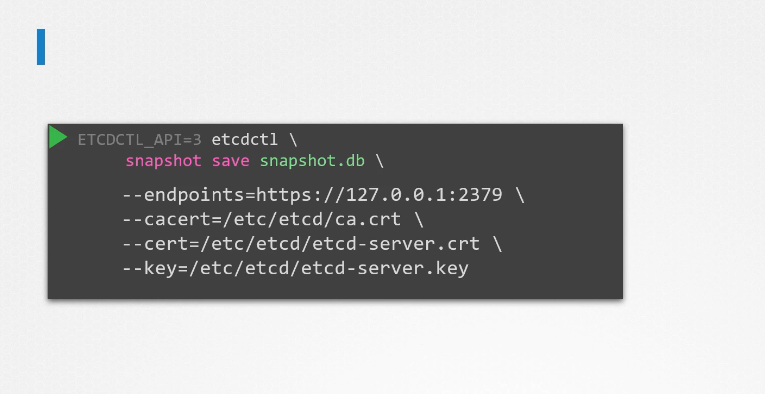
With all the etcd commands, remember to specify the certificate files for authentication,
specify the endpoint to the etcd cluster and the CS certificate,
the etcd server certificate, and the key.
So we have seen two options, a backup using etcd, and a backup by querying the Kube API server.
Now both of these have their pros and cons. Well, if you’re using a managed Kubernetes environment, then, at times, you may not even access to the etcd cluster.
In that case, backup by querying the Kube API server is probably the better way.